La strategia per scoprire il tipo di veicolo analizzando i dati grezzi registrati dal DAS si compone di due fasi. Il primo – la fase di pre-processing – riduce la dimensionalità dei dati e filtra il rumore proveniente dall’ambiente cittadino. Il secondo – la fase di rilevamento del tipo di veicolo – si basa su un algoritmo di raggruppamento per fornire una partizione dei veicoli in base alla loro tipologia.
La fase di pre-processing consiste nell’eseguire una decomposizione wavelet bidimensionale della matrice che rappresenta il segnale.
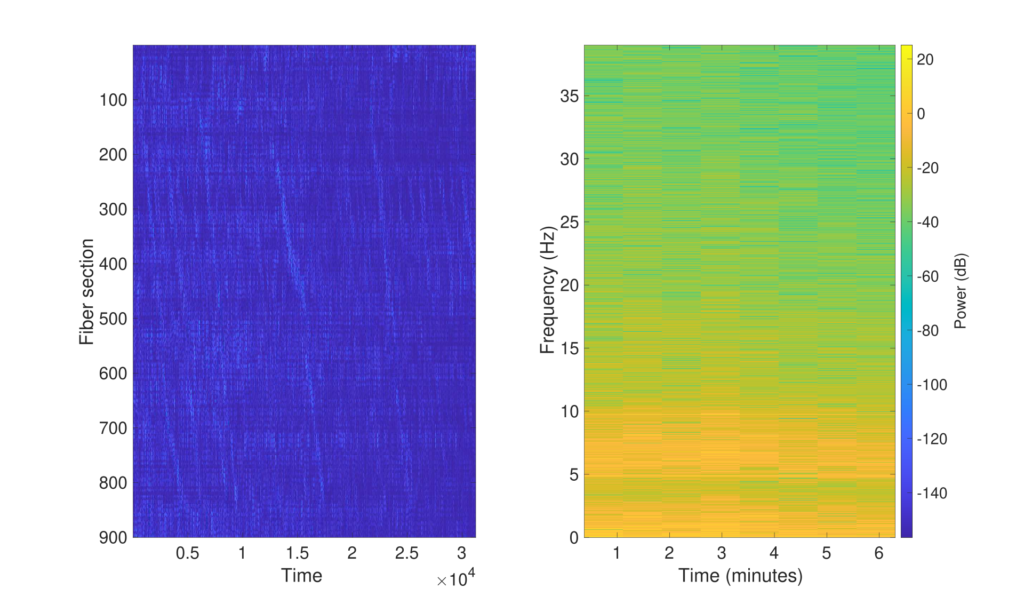
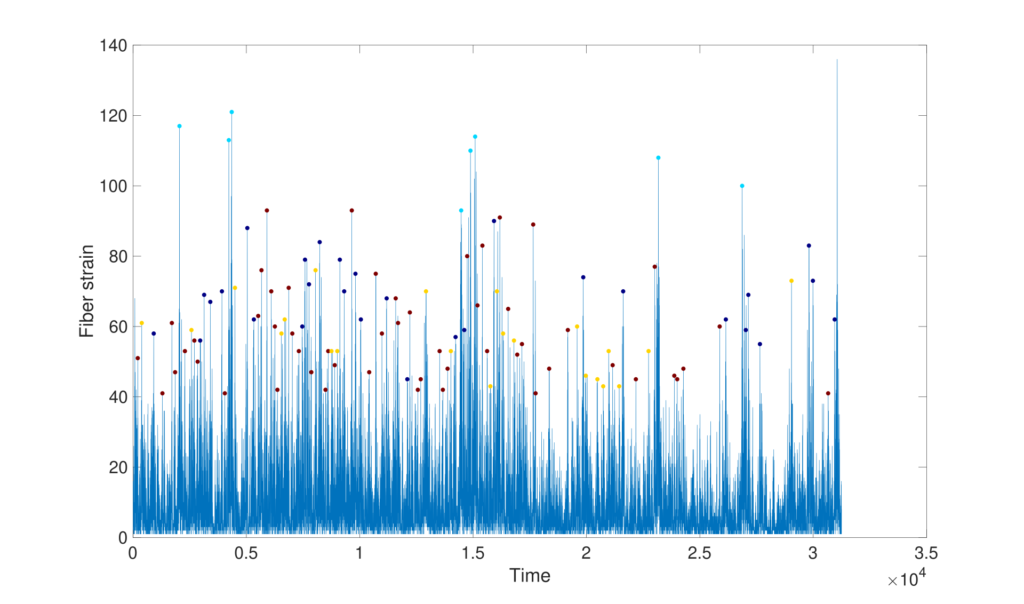
L’individuazione invece del passaggio delle macchine e la categorizzazione della tipologia vengono fatte attraverso un algoritmo di clusterizzazione
Sviluppo Applicazione Web Per la Gestione dei POI
Sviluppo Applicazione Mobile per l’utilizzo dell SmartDPI
Sviluppo QSData HUB
Il progetto Quick & Smart ha sicuramente una caratteristica importante che consiste nella collezione e distribuzione di informazioni/conoscenza. Queste informazioni sono messe a disposizione sia degli utenti che fruiscono dei servizi offerti, come ad esempio durante il tracking del Sentiero degli Dei, e sia degli operatori addetti alle analisi dei dati sul traffico raccolti tramite il sistema DAS.
Vista l’importanza che il dato, inteso come informazione/conoscenza, rappresenta nell’ambito del progetto, un’apposita applicazione è stata realizzata per permetterne la ricezione, persistenza e la consultazione. Questa applicazione permetterà così la fruizione, secondo flussi predeterminati, del database da parte delle applicazioni stesse che costituiscono il frontend del progetto.
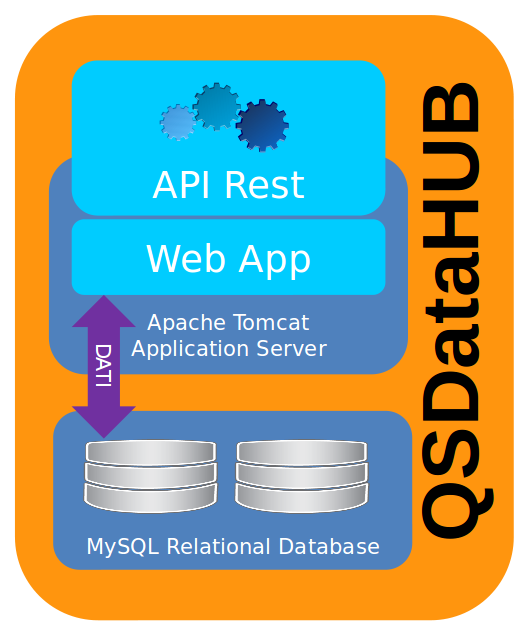
Il Quick&Smart DataHUB (così denominato ed in sintesi QSDataHUB) è una soluzione costituita da un database server relazionale MySQL (nel suo fork MariaDB) e una Java web application, in esecuzione su un application server Apache Tomcat, che espone una serie di API REST per la ricezione/persistenza e consultazione delle informazioni all’interno del database relazione. Per supportare un caso specifico di inserimento dati, è stata implementata anche una pagina web che permette l’upload dei dati provenienti dalle centraline del DAS tramite un file di testo strutturato, oltre che attraverso le già citate API REST.
Il database server si occupa, quindi, del servizio di persistenza, mentre le API REST si occupano del flusso di interscambio con le applicazioni che gestiscono il dato.
L’utilizzo di API REST rappresenta, inoltre, una scelta di progettazione aperta alle future esigenze di crescita e customizzazione della soluzione e del progetto.
Per la prototipazione della soluzione si è scelto di integrare tutte le componenti costituenti il già citato middleware opensource (MySQL e Tomcat con la Web Application che espone le API REST) in una virtual machine Linux Debian che è stata portata in produzione sulla stessa infrastruttura cloud privata sulla quale sono in esercizio le altre applicazioni del progetto.